
先日、SnowflakeのSnowPro Core認定に合格しました。
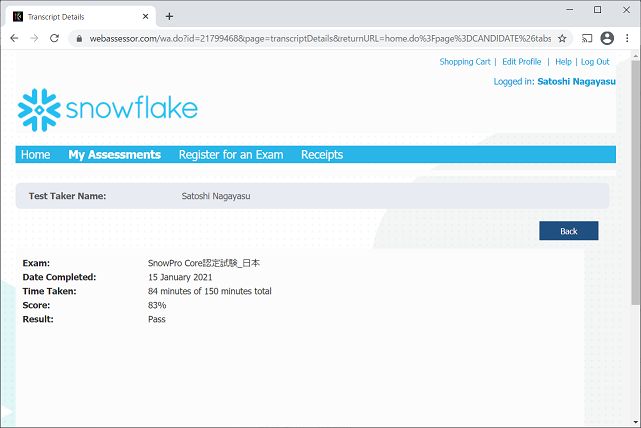
どのように勉強していたのかを備忘録的に残しておきます。
スキル、経験値としては、
です。
まずはともあれ、どのような試験なのか、何をどう勉強するべきなのかを把握するために、SnowProのStudy Guideを見ます。 Snowflake Universityというラーニングサイト(サービス)があるので、そちらのアカウントを作成しておく必要があります(無料)。
こちらをざっくり見ると、Coreのスコープは
とありましたので、この辺の領域について、試験では100問を120分で回答する必要があります。
ちなみに、試験には「SnowPro Core認定試験_日本」という日本人向けの試験がありますが、こちらの試験は問題文も選択肢もすべて英語なのですが、日本人向けに「試験時間は150分、合格のための正答率も若干調整」されているそうです。(自分の試験でも、試験時間が150分なのは確認できましたが、正答率の違いについては確認できませんでした)
なお、日本語の試験は準備中のようです。
英語圏でない日本人向けという意味で、試験時間や正答率を多少考慮しています。ちなみに、日本語での試験は準備中です。
— Mineaki Motohashi (@mmotohas) January 15, 2021
Snowflakeでは30日有効のトライアルアカウントを無料で作成できます。400USD相当まで使えるようです。
クレジットと残日数を消費していくので、自分は最初はトライアルアカウントを作成せずに学習を進めていたのですが(ケチ)、実際に動かしてみると思ったほどクレジットも消費しなかったので、もう少し早めに手を動かしてみれば良かったかな、と思いました。
Snowflakeの学習を始めようと思った時期、ちょうどCloud Data Summit 2020が開催されており、こちらの動画も活用させていただきました。
Snowflakeの概要や設計思想、現在地をざっくり把握するのにかなり役に立ったように思います。
さて、では本格的に勉強を始めます。
Snowflake Universityに日本語のコースがあるのですが、この中にハンズオンのコースがありますので、まずは最初の雰囲気を把握するためにこちらを受講します。
字幕付きの動画を見て、ドキュメントを読んで、クイズに応えていく形式です。サクサク進めれば数日で完了できると思います。
Study Guideには各種学習リソースへのリンクがありますので、その内容を確認しながらインプットしていきます。
基本的には、
という形になります。
Study Guideには以下の領域のコンテンツが整備されています。
この段階でSnowflake Universityにある模擬試験「SnowPro Core Sample Exam Questions」を受けたら、25/30で83.3%でした。(合格ラインは80%)
せっかくトライアルアカウントがありますので、こちらを使ってデータパイプラインを作ってみました。
をすることで、
ということが自動的にできるようになります。(この話は後日別途書く予定です)
このプロセスを通して、何ができるのか、そのために何が必要なのか、をある程度把握できるようになりました。
いつも何かのセールをしていることでおなじみのUdemyに、SnowPro Coreの模擬試験集があったので、こちらを購入して活用しました。
ちなみに、試験の問題セットは全部で6セットあり、それぞれ
とあるのですが、自分は時間の都合上「Test 3」までを1回ずつしかこなせませんでした。
但し、「Test 1」、「Test 2」、「Test 3」ではそれぞれ出題される領域が異なっていましたので、まんべんなく学習するにはすべて受けて、間違った部分を確認しておいた方がいいと思います。
なお、これらの模擬試験は本番試験の直前に受けたのですが、
と、合格ラインとはほど遠い状態でありました。(それぞれのテストで出題される領域が偏っているので、苦手な領域に当たると点数が大きく下がるのです)
そういう観点でも、試験の前にはこれらの模擬試験を受けて自分の苦手領域を把握してマニュアルを確認しておく、などするのが良いと思います。
模擬試験では正答はもちろん、解説やマニュアルへのリンクなども提供されており、自分の学習には非常に役に立ちました。
本番試験は、Kryterionの「Online Proctored(遠隔監視オンライン試験)」を選びました。
テストの詳細については、以下も参考になるかと思います。
注意点としては、
ちょっとトラブルもあったのですが、まぁどうにかなりました。Chatでサポートしてくれた方に感謝。
という感じで、今回はどうにか合格ラインには到達したのですが、出題された問題と自分の理解レベルを比較すると、
当たりの領域が弱いかな、と感じました。
自分が学習してきた方法の中では、これらの領域はあまり手厚くカバーされていなかったので、これらの機能を使って自分でデータパイプラインを作ってみるなど、何らかの形で補完しておいた方が良かったかもしれません。(試験対策という意味でも、知っていれば確実に点が取れるものも多いので)
あと、(処理履歴、Fail-safe、Time Travel、キャッシュなど)各種のデータ保持期間は覚えるしかないので、チートシートなどを活用すると良いのではないかと思います。
ちなみに自分は、このチートシートの存在を試験を受けた後に知りました。。
また、上記のチートシートも便利そうではあるのですが、Snowflakeの特長はその豊富なメタデータとその活用にあると感じますので、各種メタデータとそのアクセス方法(SQLクエリ)を集めたチートシートを作っておくと、開発や運用の時に役に立ちそうだな、と思いました。
では。
先日、AWSのData Analytics Specialtyに合格しました。
どのように勉強していたのかを備忘録的に残しておきます。
スキル、経験値としては、
です。
Cloud AcademyにData Analyticsにフォーカスしたコースがあるので、こちらを受講します。
但し、こちらはPreview版(受講時点)なので、内容が変わっていく可能性があります。私が受講している間にもコンテンツが追加されていました。
私の場合、所要期間は1ヵ月程度でした。
それなりに時間はかかるのですが、ハンズオンラボなどを使ってAWSのデータ関連サービスを網羅的に触ってみる機会ですので試してみる価値はあるかと思います。
最後に模擬試験があるのですが、これになかなか苦戦して、3回目でどうにかパスしました。
という感じでした。
Cloud AcademyのコースはPreview版なので、カバレッジや内容にやはり多少の不安があったので、AWS JapanのBlackbeltの資料を一通り眺めました。
以下は自分で作っていたリンク集です。
基本的には試験のカバーしている範囲の資料を「フムフム」と眺めていく程度でした。
それでもある程度の不安が残ったので、試験の直前にUdemyのこちらのコースの講義動画を一通り眺めました。
タイトルにある通り、本来はハンズオンをしながら学習するコースなのですが、時間がなかったため、不足している知識をカバーすべくひたすら動画だけを眺めてインプットする、ということを行いました。
つまりは一夜漬けです。
すさまじい勢いのマシンガントークで、非常に幅広い内容の説明を進めていく講義は、本当に一夜漬けにピッタリでした。
直前のBlack Fridayのセールで安く買ってあったのですが(1,200円)、これでかなり助かった気がします。
新型コロナの影響もあり、自分は自宅で受験できるピアソンVUEの「遠隔監視オンライン試験」で受験しました。
要件の詳細はピアソンVUEのOnVUEのページを参照してください。
個人的には、先日のGoogle Data Engineerの試験で自宅からの試験を受けていたので、それほど惑わずに実施できました。
今回使ってみたCloud Academyは本当によくできていると思いました。
きちんと設計されたLearning Pathに沿って一貫性のあるコンテンツが整備されていて、ハンズオンラボもあるし、継続的なクラウド学習のために常用するにはいいサービスだと感じました。 そういう使い方をするなら、確かにかなり安いと思います(お、値段以上)。自分はどちらかというと体系的な学び方が好きなので、自分に向いている感じもあります。
一方で、Udemyは玉石混合感があって、当たりのコンテンツは本当に当たりなのですが、必ずしも自分が必要とする領域のコンテンツがあるとは限らなくて、その辺は難しいかなと思います。(今回使ったUdemyのコースについて言えば、文句なく当たりでした。Cloud Academyでカバーできてなかったトピックとかもカバーできて助かりました。主観ですが)
Cloud AcademyはBlack Fridayのセールで一年分サブスクリプションを購入してしまったので、もう少し深堀りしたり幅出ししたりするために、継続的に使ってみようと思います。
では。
先月下旬に、GCPのProfessional Data Engineerに合格しました。
もともとは、「BigQueryを多少は使っていた」、「Cloud Composer(Airflow)を多少使ったことがあった」程度で、それほどGCPのサービスを使い倒しているというわけではないのですが、どのように勉強していたのかを備忘録的に残しておきます。
CourseraにGoogle CloudのProfessional Data Engineerにフォーカスしたコースがあるので、こちらを受講します。
私が受講した時は英語だけだった気がしますが、今見てみると日本語もあるようです。
私の場合、所要期間は2ヵ月程度でした。
それなりに時間はかかるのですが、GCPのデータ関連サービスを網羅的に触ってみる機会ですので試してみる価値はあるかと思います。特にDataflowなどはなかなか面白かったです。
QwiklabsにProfessional Data Engineer向けのクエストがありますので、そちらをこなします。
こちらは講義は無く、ひたすら手を動かしてくハンズオンのコースです。
公式の模擬試験がありますので(質・量ともに本番のサブセットですが)、こちらを受けて自分の現在のレベルを確認します。
純粋にデータエンジニアリングのテクニカルな話題だけではなく、セキュリティやコスト管理などの話も出てきますので、不慣れであればその辺を他の教材などを使って確認しておきます。
自分の場合、この模擬試験を受講した時点で正答率は65%程度でした。
新型コロナの影響もあり、自分は自宅で受験できる「遠隔監視オンライン試験」で受験しました。
要件の詳細は認定試験のページを参照してください。
MOOCsの普及とクラウドの隆盛と新型コロナが重なって、本当にいろいろなものがオンラインで完結するようになったな、という印象を改めて受けました。
利用するIT基盤はオンラインで、それを学ぶトレーニングもオンラインで、ハンズオントレーニングもオンラインで、試験もオンラインで、と、すべて自宅からの作業だけで完結してしまいました。
新型コロナで自宅にいる時間が少し長くなった分、スキルアップに使える時間が少し増えたのだと思えば、それはそれでアリなのかもしれません。興味のある方はトライしてみてもらえればと思います。
では。
SONYのXperia Z3 Tablet Compactを愛用しています。外出中の読書や情報収集にはもっぱらこの端末を使っています。
使っているアプリは
くらいで、集中を妨げられないようにTwitter/Facebookなどのソーシャル系アプリは入れていません。Googleアカウントも最近削除したので、カレンダーもメールも何もありません。
が、ブラウザで読んでいるWebページをTwitterに投げたい場合も多々あり、そういう時の方法としてどうしたものか、考えあぐねていました。(TwitterやFacebookのアプリは入れていないので)
で、先日、
という記事が流れてきたのを見かけ、「これなのでは?」という気がしたので試してみました。
Twitterで共有するためのBookmarkletのコードは以下になります。
javascript:void((function(undefined) {
p = "text=" + encodeURIComponent(document.title) + "&url=" + encodeURIComponent(document.location);
window.open("https://twitter.com/intent/tweet?" + p);
})());
これをpackerで1行にまとめると以下のようになります。
javascript:void((function(undefined){p="text="+encodeURIComponent(document.title)+"&url="+encodeURIComponent(document.location);window.open("https://twitter.com/intent/tweet?"+p)})());
ついでに、Facebookで共有するためのコードは以下のようなもので、
javascript:void((function(undefined) {
p = "u=" + encodeURIComponent(document.location);
window.open("https://www.facebook.com/sharer/sharer.php?" + p);
})());
packerにかけると以下のようになります。
javascript:void((function(undefined){p="u="+encodeURIComponent(document.location);window.open("https://www.facebook.com/sharer/sharer.php?"+p)})());
上記のBookmarkletをPCのFirefoxに登録したところ、想定通り動作したのですが、そのままAndroidのChromeで実行しても動作しませんでした。どうも単にブックマークリストから開こうとしただけでは起動できないようです。
というわけで、以下の記事を参考に呼び出し方を変えてみました。
すると、以下のように期待通りの動作をしてくれるようになりました。
まず、Webページを開きます。
アドレスバーにブックマーク名(今回の場合は Share on Twitter)の一部をタイプ。プルダウンに出てきたら、それをクリック。
Bookmarkletが起動してTwitter上で共有できるタブが開く。
これで、ソーシャルアプリの入っていない私のタブレットでも簡単にTwitter上で共有できるようになりました。
めでたしめでたし。
「入門オペレーションズ・リサーチ」の演習問題を解いてみるシリーズ。第二弾。
Jupyter Notebookに一通り書いております。こちら。
またもや解答が書かれていなかったので難儀しているのと、結局、maximizeする問題だったのか、minimizeする問題だったのかが、よく分からなかった。
鶏肉の使用量を最小化、みたいな問題設定をすればいいのだろうか。
注:同じ内容のJupyter Notebookはこちら。
入門オペレーションズリサーチ の「第12章 仕事の効率を高める 線形計画」の例題をPythonで解いてみる。
参考: PuLP による線型計画問題の解き方ことはじめ - Qiita
| 牛乳 | 作業時間 | 儲け | |
|---|---|---|---|
| エスプレッソアイス | 100cc | 7分 | 250円 |
| ラズベリーアイス | 150cc | 5分 | 300円 |
まず、PuLPのモジュールをインポートする。
import pulp
エスプレッソアイスの生産量を x1 、ラズベリーアイスの生産量を x2 とする。
変数の定義時に最小値最大値を設定する必要があるが、最大値はここでは便宜上 9999 と置く。(PuLPを使う場合、変数の定義の時点でそれが制約の一部を兼ねる模様)
x1 = pulp.LpVariable('x1', 0, 9999, 'Integer')
x2 = pulp.LpVariable('x2', 0, 9999, 'Integer')
この時、儲けの合計 (250 * x1 + 300 * x2) を最大化したい。(目的)
problem = pulp.LpProblem('アイス増産計画', pulp.LpMaximize)
# 目的関数
problem += 250 * x1 + 300 * x2
次に制約条件を追加していく。
まず、牛乳の使用量の制約。牛乳は合計8000ccまでしか使えないので、各アイスにおける使用量の合計の上限を8000ccとする。
# 使用量の制約条件
problem += 100 * x1 + 150 * x2 <= 8000
次に生産時間の制約。増産に使える時間は延べ360分なので、各アイスにおける生産時間の合計の上限を360分とする。
# 生産時間の制約条件
problem += 7 * x1 + 5 * x2 <= 360
書籍で記載されている x1 および x2 が正の値 (x1, x2 >= 0) は変数定義時に最小値として設定してあるので、割愛する。
解く。
status = problem.solve()
print(pulp.LpStatus[status])
Optimal
Optimal が出ていれば解けている。
問題を改めて見てみる。
print(problem)
アイス増産計画:
MAXIMIZE
250*x1 + 300*x2 + 0
SUBJECT TO
_C1: 100 x1 + 150 x2 <= 8000
_C2: 7 x1 + 5 x2 <= 360
VARIABLES
0 <= x1 <= 9999 Integer
0 <= x2 <= 9999 Integer
求めた値を見てみる。
まずは x1 、エスプレッソアイスの生産量。
x1.value()
23.0
次に x2 、ラズベリーアイスの生産量。
x2.value()
38.0
つまり、制約条件のもとで、エスプレッソアイスを 23、ラズベリーアイスを 38 生産した時に、儲けが最大化される。
と思われるが、例題に解答が載っていないので、合っているかどうかが分からない(ェ
以上。
PostgreSQL関連のブログ は既に持ってはいるものの、それ以外の雑多なテクニカルなネタをどこに書こうか、ずいぶん長いこと迷ったり試行錯誤したりしていたのですが、Github PagesとJekyllを使ってみることにしました。
というわけで、JekyllとGithub Pagesを使って立ち上げてみました。
ここに技術的なメモとしていろいろ残していくつもりです。
スタイルやレイアウトなどの細かい調整は、これから少しずつしていこうと思います。